


发布日期:2024-09-25 07:25 点击次数:67

上周写了一个node+experss的爬虫小初学。今天持续来学习一下妈妈我心中的维纳斯,写一个爬虫2.0版块。
此次咱们不再爬博客园了,咋玩点新的,爬爬电影天国。因为每个周末都会在电影天国下载一部电影来望望。
talk is cheap,show me the code!
捏取页面分析
咱们的倡导:
1、捏取电影天国首页,得回左侧最新电影的169条畅通
2、捏取169部新电影的迅雷下载畅通,况湮灭发异步捏取。
具体分析如下:
1、咱们不需要捏取迅雷的所有这个词东西,只需要下载最新发布的电影即可,比如底下的左侧栏。一共有170个,撤回第一个(因为第一个内部有200部电影),一共有169部电影。
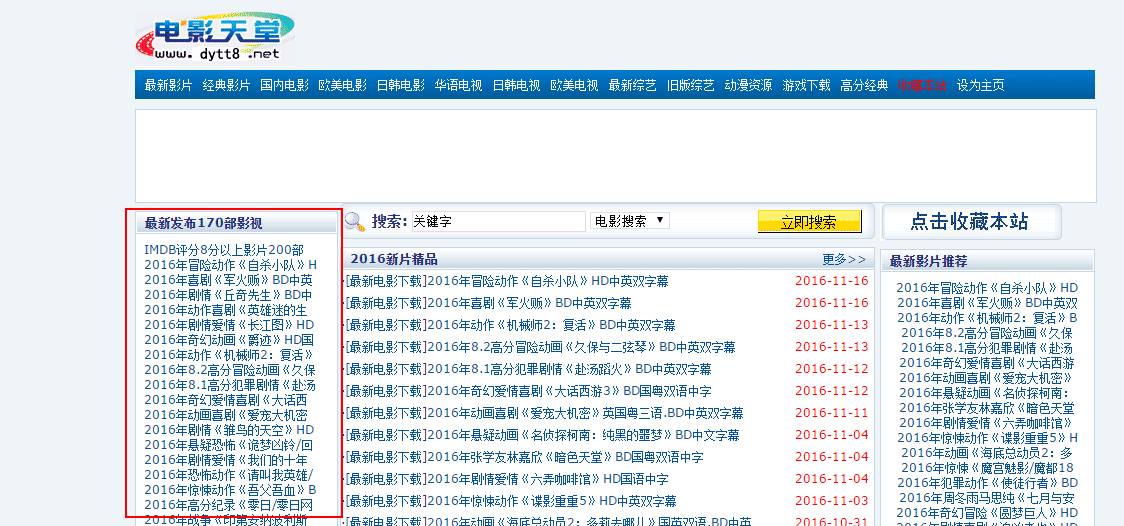
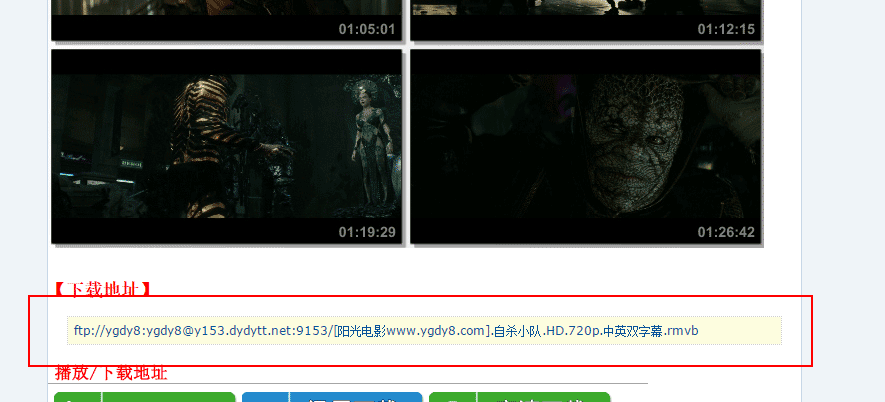
2、除了捏取首页的东西,咱们还要捏取点进去之后,每部电影的迅雷下载畅通
环境搭建
1、需要的东西:node环境、express、cherrio 这三个都是上一篇著作有先容的,是以这里不再作念先容:点击检验
2、需要装置的新东西:
superagent:
作用:跟request差未几,咱们不错用它来得回get/post等恳求,况兼不错开辟关系的恳求头信息,比拟较使用内置的模块,要浅薄许多。
用法:
superagent-charset:
作用:料理编码问题,因为电影天国的编码是gb2312,爬取下来的汉文会乱码掉。
用法:
async:
作用:Async是一个经过收尾用具包,提供了径直而宽阔的异步功能,在这里四肢处理并发来调用。
吻玉足用法:这里需要用到的是:async.mapLimit(arr, limit, iterator, callback)
mapLimit不错同期发起多个异步操作,然后一王人恭候callback的复返,复返一个就再发起下一个。
arr是一个数组,limit并发数,将arr中的每一项挨次拿给iterator去扩充,扩充成果传给临了的callback
eventproxy:
作用:eventproxy 起到了计数器的作用,它来帮你料理到底异步操作是否完成,完成之后,它会自动调用你提供的处理函数,并将捏取到的数据当参数传过来。
举例我率先捏取到电影天国首页侧栏的畅通,才不错接着捏取畅通内部的本色。具体作用不错点这里
用法:
运行爬虫
主要的法子在app.js这里,是以看的话不错主要看app.js即可
1、率先界说一些全局变量,该引入的库引进来
2、运行爬取首页迅雷首页:
在这里,咱们先捏取首页的东西,把首页捏取到的页面本色传给 getAllMovieLink和highScoreMovie这两个函数来处理,
getAllMovieLink得回到了左侧栏除了第1部的电影的169电影。
highScoreMovie为左侧栏第一个畅通,内部的都是评分比较高的电影。
上头的代码中,咱们弄了一个计数器,当它扩充完之后,咱们就不错扩充与‘get_topic_html‘名字对应的经过了,从而不错保证在扩充完首页的捏取使命之后,再扩充次级页面的捏取使命。
ep.emit('get_topic_html', 'get '+page+' successful');
highScoreMovie设施如下,其实咱们这里的作用不大,仅仅我统计一下高评分电影首页的信息,懒的持续捏取了
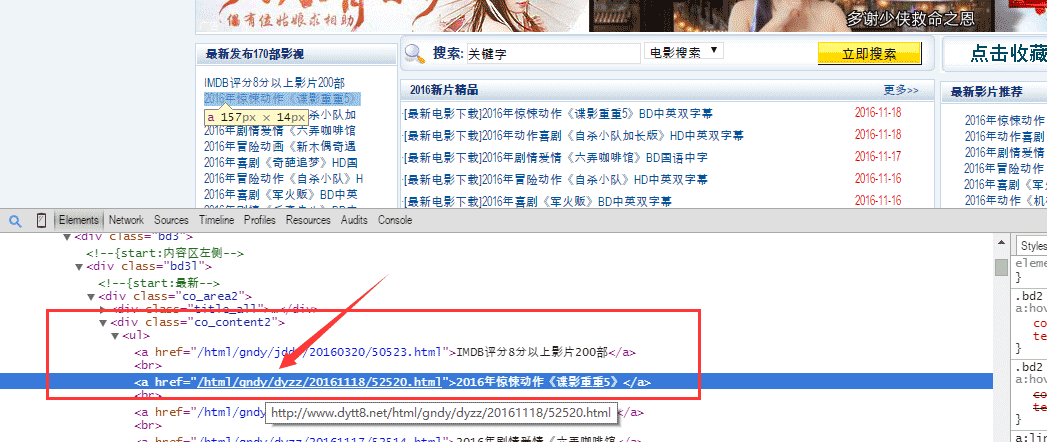
3、区别出左侧栏的信息,
如下图,首页中,笃定页的畅通都在这里$('.co_content2 ul a')。
因此咱们将左侧栏这里的笃定页畅通都遍历出来,保存在一个newMovieLinkArr这个数组内部。
getAllMovieLink设施如下:
4、对得回到的电影笃定页进行爬虫,索要灵验信息,比如电影的下载畅通,这个是咱们所存眷的。
率先是async.mapLimit对所有这个词笃定页作念了一个并发,并发数为5,然后再爬取笃定页,爬笃定页的过程其实和爬首页的过程是不异的,是以这里不作念过多的先容,然后将灵验的信息打印到页面上。
5、扩充号召之后的图如下所示:
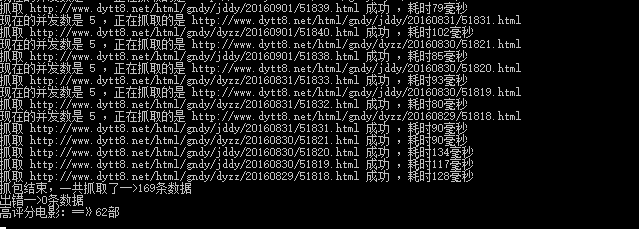
浏览器界面:
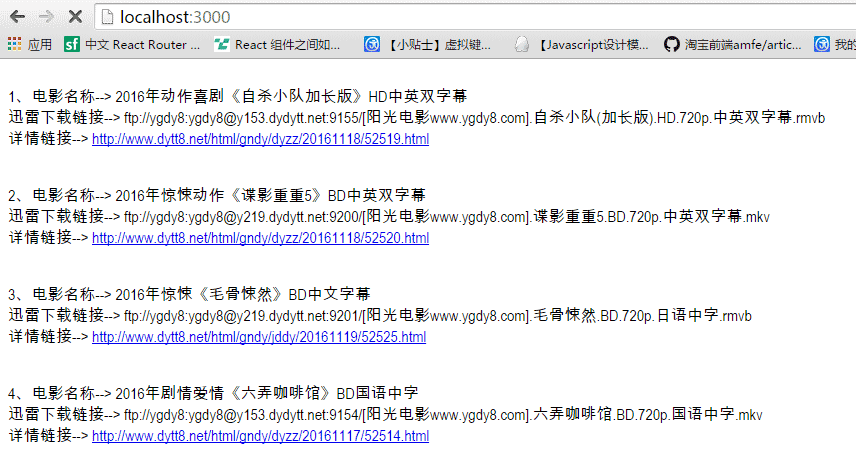
这么,咱们爬虫的略略升级版就就完成啦。可能著作写的不是很明晰,我如故把代码上传到了github上,不错将代码运行一遍,这么的话比较容易理会。后头若是只怕刻,可能会再搞一个爬虫的升级版块,比如将爬到的信息存入mongodb,然后再在另一个页面展示。而爬虫的法子加个定时器,定时去捏取。
备注:若是运行在浏览器中的汉文乱码的话,不错将谷歌的编码开辟为utf-8来料理;
代码地址:https://github.com/xianyulaodi/mySpider2
有误之处妈妈我心中的维纳斯,宽宥指出
您可能感兴味的著作: node puppeteer爬虫爬取电影网站及生成pdf文档示例 手把手教你用Node.js爬虫爬取网站数据的设施 讹诈node.js写一个爬取知乎妹纸图的小爬虫 node.js爬虫爬取拉勾网职位信息 NodeJs爬虫框架Spider基础使用教程 node.js竣事浅薄爬虫示例详解 nodejs作念个爬虫爬取腾讯动漫本色浅薄竣事上一篇:激情网 好意思公布2020惡市場名單 台灣「電影天国DYTT8」再被點名
下一篇:真实 勾引 BT9527电影天国